-
[파이썬/Python] 파이썬으로 크롤링하기Python 2021. 6. 11. 10:39
파이썬으로 크롤링을 하는 것이 굉장히 쉽다고 알고 있어서 도대체 얼마나 쉽지? 라는 생각에
파이썬으로 크롤링을 해봤다.
목표
- 파이썬으로 크롤링하기
- 플라스크(Flask) 활용하기
- 크롤링한 데이터를 JSON으로 리턴하는 API 만들기 -> (플라스크 활용)
크롤링 대상 페이지
- http://ncov.mohw.go.kr/bdBoardList_Real.do?brdId=1&brdGubun=13&ncvContSeq=&contSeq=&board_id=&gubun=
- 위의 페이지는 코로나 시도별 발생동향을 알려주는 페이지다.
1. 모듈 import
from flask import Blueprint from bs4 import BeautifulSoup import json import requests일단 필요한 모듈들을 import 한다.
import한 모듈에 대한 설명은 해당 모듈을 사용할 때 설명하겠다.
2. 해당 URL의 HTML을 읽어서 파싱한 HTML을 반환 해주는 함수 작성하기
#해당 url의 html을 BeautifulSoup 객체로 리턴 def get_html(url:str) -> BeautifulSoup: html = requests.get(url) soup = BeautifulSoup(html.text, 'html.parser') return soup- 파라미터로 요청할 url을 받는다, 요청할 때 import한 requests 객체를 사용한다.
- 해당 url의 html 정보를 받아서 import한 BeautifulSoup 객체를 사용한다. (BeautifulSoup 객체는 html을 파싱하고 편리하게 사용할 수 있게 여러 함수를 제공한다.)
3. BeautifulSoup 객체를 받아서 특정 tag (html)의 정보를 반환 해주는 함수 작성하기
#soup 객체에서 특정 css data 리턴 def select_area(area_css:str, soup:BeautifulSoup) -> list: html = soup.select(area_css) rtn = [] for row in html: row = row.get_text(separator, strip=True).split(separator) for i in range(len(row)): if not str(row[i])[0].isdigit(): rtn.append({"area": row[i], "total": str(row[i+1]).replace(',', '')}) return rtn- 파라미터로 BeautifulSoup 객체에서 특정할 css (area_css)와, BeautifulSoup 객체를 받는다.
- 파라미터로 받은 area_css를 통해 BeautifulSoup 객체에서 특정한다.
- 특정한 BeautifulSoup 객체에서 원하는 정보만 list로 반환한다.
4. JSON으로 반환하는 API 구현하기
@bp.route('/crawling') def crawling(): soup = get_html("http://ncov.mohw.go.kr/bdBoardList_Real.do? brdId=1&brdGubun=13&ncvContSeq=&contSeq=&board_id=&gubun=") seoul = select_area("div#zone_popup1 tbody", soup) busan = select_area("div#zone_popup2 tbody", soup) daegu = select_area("div#zone_popup3 tbody", soup) incheon = select_area("div#zone_popup4 tbody", soup) gwangju = select_area("div#zone_popup5 tbody", soup) daejeon = select_area("div#zone_popup6 tbody", soup) ulsan = select_area("div#zone_popup7 tbody", soup) sejong = select_area("div#zone_popup8 tbody", soup) gyeonggi = select_area("div#zone_popup9 tbody", soup) gangwon = select_area("div#zone_popup10 tbody", soup) chungbuk = select_area("div#zone_popup11 tbody", soup) chungnam = select_area("div#zone_popup12 tbody", soup) jeonbuk = select_area("div#zone_popup13 tbody", soup) jeonnam = select_area("div#zone_popup14 tbody", soup) gyeongbuk = select_area("div#zone_popup15 tbody", soup) gyeongnam = select_area("div#zone_popup16 tbody", soup) jeju = select_area("div#zone_popup17 tbody", soup) return json.dumps({'seoul': seoul, 'busan': busan, 'daegu': daegu, 'incheon': incheon, 'gwangju': gwangju, 'daejeon': daejeon, 'ulsan': ulsan, 'sejong': sejong, 'gyeonggi': gyeonggi, 'gangwon': gangwon, 'chungbuk': chungbuk, 'chungnam': chungnam, 'jeonbuk': jeonbuk, 'jeonnam': jeonnam, 'gyeongbuk': gyeongbuk, 'gyeongnam': gyeongnam, 'jeju': jeju}, indent=4, ensure_ascii=False)- 특별한 사항은 없고 각 지역의 데이터를 가져와서 마지막에 json으로 리턴한다.
- 여기서 import한 json과 Blueprint를 사용하는데 json은 데이터를 json 형태로 쉽게 다룰 수 있게 여러 함수를 제공하고 Blueprint는 Flask를 참고하길 바란다..(Spring의 Controller라고 생각하면 편하다.)
5. 결과

- 만든 프로그램을 Flask를 통해 로컬 환경에서 실행 후 API를 postman으로 요청한 결과는 다음과 같다.(JSON으로 잘 반환 받았다!)
6. 설명
우선 크롤링 대상의 페이지와 html 구조를 살펴보면 다음과 같다.
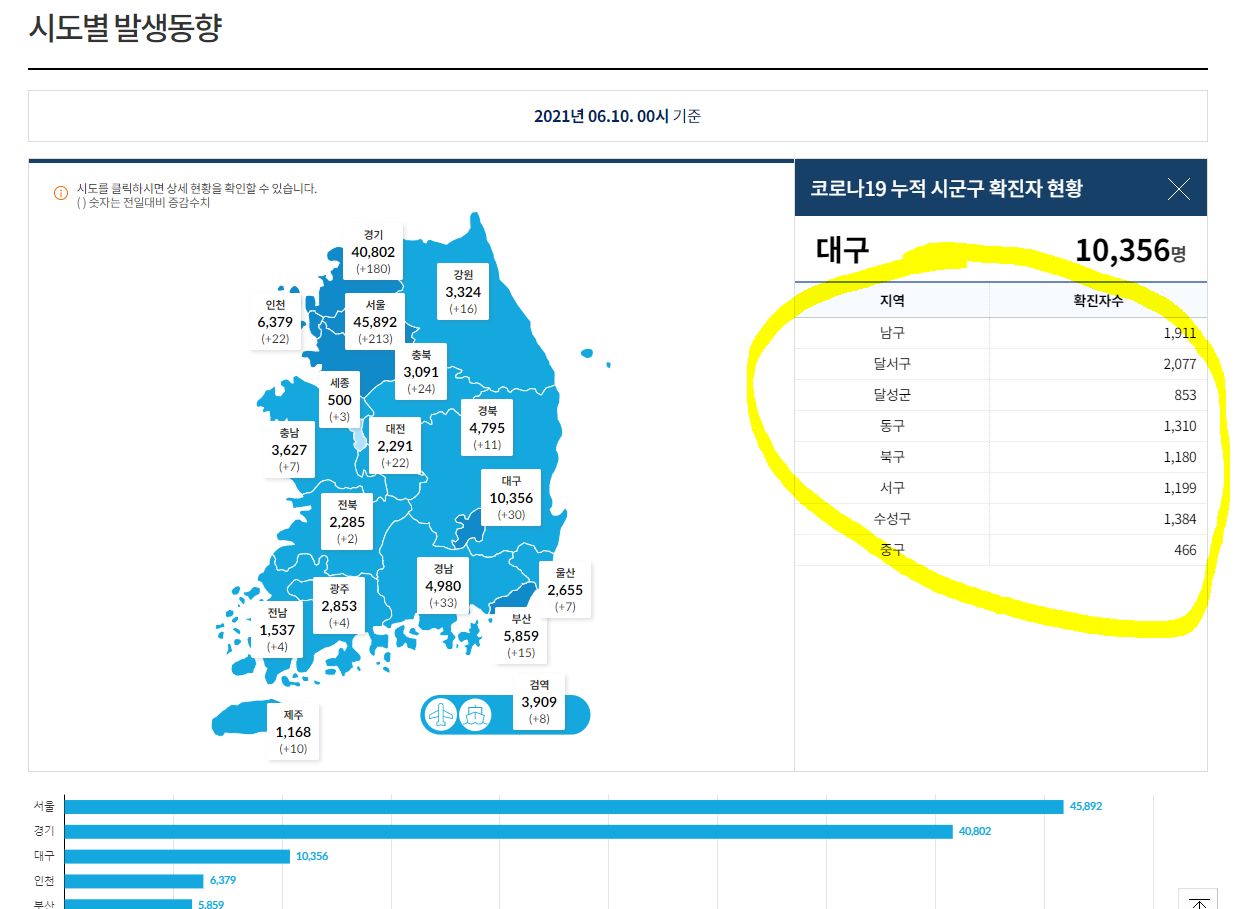

왼쪽 부터 페이지 사진, html 구조 사진 필자는 왼쪽 사진의 노란색으로 표시한 부분의 데이터를 가져오고 싶었고
그에 대한 html 구조는 오른쪽 사진과 같다.
대략적인 동작 순서
1. 원하는 페이지의 html을 요청한다.
def get_html(url:str) -> BeautifulSoup: html = requests.get(url) soup = BeautifulSoup(html.text, 'html.parser') return soup2. Jquery의 selecting처럼 원하는 데이터가 위치한 해당 html을 특정한다.
#3번 함수의 구문 html = soup.select(area_css)3. 데이터 정제 과정(상황에 따라 다름)
for row in html: row = row.get_text(separator, strip=True).split(separator) for i in range(len(row)): if not str(row[i])[0].isdigit(): rtn.append({"area": row[i], "total": str(row[i+1]).replace(',', '')})4. JSON으로 반환한다.
return json.dumps(data, indent=4, ensure_ascii=False)마치며
일단 파이썬으로 크롤링하는 과정은 정말 간단하다.
다만 해당 html을 파악하고 데이터를 정제하는 과정이 살짝 단순 반복성이 요구된다.
파이썬이 지원하는 다양한 모듈(라이브러리)들이 사용자 친화적으로 잘 만들어졌다는 생각이 들었고,
쉬워서 재밌다..
'Python' 카테고리의 다른 글
[파이썬/Python] 파이썬 데크/덱 (deque) 자료구조 알아보기 (0) 2021.06.22 [파이썬/Python] 파이썬의 정렬 방법들 (python sort) (0) 2021.06.12 [파이썬/Python] 파이썬 for문 index, value 동시에 접근 하기 (0) 2021.06.07 [파이썬/Python] 파이썬의 접근 제어자 (private) (0) 2021.06.03